Claims of retribution aside, one steelman is that Mythos is likely the most capable model that's usable by folks like the NSA [1], and decision-makers across the USG and industry partners have seen a stream of reports of Mythos successfully finding serious vulnerabilities over the past couple months due to Glasswing.
So even if GPT 5.5 is just as capable in these scenarios (which, imo, it largely is), it is not known by the government apparatus as having the same capabilities.
Personally, I think we crossed the threshold of capabilities with Opus 4.6 [2], which translated to an even more capable open-weight GLM 5.1 (which it is rumored to have distilled Opus 4.6) [3][4]. But the USG and its partners aren't fully rational actors with perfect data, so it's possible they're only viscerally aware of these capabilities in the context of Mythos.
I doubt that the capabilities of GPT-5.5-cyber aren’t known by the US government considering OpenAI is their primary LLM partner after Anthropic had concerns about using models for autonomous weaponry and mass surveillance of US citizens. If anything, they should have more experience in GPT-5.5s full feature set due to longer access and may even already have GPT-5.6 access.
Hanlon's razor. Are the people with the right access talking to the right people? Wouldn't be the first time for miscommunication in the executive branch.
Fair point, not unlikely, though my personal assumption is that, like with Nvidia export controls, there will be a sudden reversal with no tangible, actual, technically based reason the second a certain person has their ring kissed...
They made a deal for access, but I'm unsure if it's usable, scaled, and has vulnerabilities attributed to it at this point. But I have no inside information here, so I could be wrong.
It sounds like you might not agree with that belief.
While I don't agree with their actions here, I do think there's sufficient reason to hold that belief.
On some fronts (e.g. security, on which you've experienced more than me), I think there are surmountable challenges. But on other fronts (e.g. bio), a single errant actor could reasonably kill millions or billions of people with sufficiently powerful AI. We don't have good defenses here, and those actors do exist.
I still don't agree with these actions, but I do think I agree with their assumptions.
The model release cards for Opus have repeatedly and consistently stressed that the model doesn't have the fiddly know-how that's required to provide meaningful assistance in possibly dangerous subfields of biology. Mythos (Fable without the overly strict guardrails) has shown improvements in things like drug design, but even then the situation isn't really that different. This risk is ridiculously overblown, and the way to manage it sensibly is to introduce meaningful oversight for actors that seek to order the actual specialized materials involved (especially any synthetically generated genes/proteins/whatever).
No, Anthropic's model cards have claimed that the models don't show considerably more uplift than previous ASL-3 models, which already showed material uplift.
I participated in the internal bioweapons uplift test for Sonnet 3.7, and even then, one non-expert got huge uplift from the model [1]. I'd consider evals a lower bound of capabilities that can be elicited from a model.
The team behind Biomni, a biomedical agent that's widely used by researchers, has continued to find consistent gains between models [2]. I trust them, because I visited them to build their HPC tool [3], which the model is quite capable of using – moreso than most grad students. The Biomni team cares a lot about about real usability for real researchers, so they have a great pulse on capabilties.
SecureBio also has some public evals [4], which have continued to show increasing uplift.
And while synthesis monitoring is a part of the solution, I think you might underestimate how much goes under the radar. See the Reedley lab incident for an example [5].
Is Anthropic still effectively throttling beneficial biomedical research? Yes! And so is OpenAI. But the underlying capability is still actually dual use.
> No, Anthropic's model cards have claimed that the models don't show considerably more uplift than previous ASL-3 models, which already showed material uplift.
Doesn't this simply amount to disagreeing about what counts as "meaningful" from a bio-safety POV? Also, even the ASL-3 deployment safeguards for Opus 4 and higher were always adopted as a mere matter of caution; it's not clear that even Anthropic believed at any point that this reflected any genuine "threshold crossing" event. So it's just not obvious how much weight we're supposed to place on that particular stance.
In normal bio, there are standardized biosafety levels, because without it there would be no standard agreement on what "meaningful" safety is. So yes, I do think there's ambiguity here.
But I don't think I've found any domain expert who thinks granting everyone raw access to the most capable models wouldn't meaningfully increase risk. OpenAI recently staffed a biological threat modeler to help quantify this risk.
(Edit: just saw your edit, this includes at Anthropic. ASL tiers were "rule-out" to exclude rather than "rule-in", so exact thresholds were murkier, but I think it's clear that models have passed that threshold by now.)
That said, there are clear steps and requirements to set up a BSL-2 or BSL-3 lab, and I think there should be similarly clear rules around model capabilties and access. The process for Anthropic and OpenAI is murky and still implictly gated on spend, which I think is holding back research.
For example, anyone who has access to a BSL-3 lab should have a clear and low-cost path to a model with corresponding capabilities, as long as they set up corresponding precautions for model access.
I think it would be a bad outcome for only frontier labs and a select few groups they choose to have access to the most capable models – which is sadly the precedent that's currently being set.
> But I don't think I've found anyone who is a domain expert who thinks granting everyone access to raw modes wouldn't meaningfully increase risk.
It depends how capable these raw models are. Biology as a field depends most on real-world knowledge, which is an expensive capability for open models targeting widespread deployment. It's quite plausible that even Opus 4 would be a lot more capable in these domains than the best universally accessible "raw models" today, quite unlike other domains such as coding or pure math. The securebio.org benchmark has spotty representation of openly available models, but it does show Kimi 2.5 being no more capable than GPT 5 mini, and clearly below o4-mini and Opus 4.0; which may be a plausible summary of where things stand today.
That's a good clarification. I've updated my comment to the "most capable models" to refer to the most recent releases.
And sure, and I love open models – I spent much of the past couple months doing additional RL on Qwen 3.6 35B A3B, Gemma 4, Kimi K2.6, and GLM 5.1. Without these open models, I'd be forced to do my research inside a frontier lab.
There's a balance to strike here, but I don't think the biological risk is overplayed. It would be very easy to accidentally cross the threshold of "meaningful" without adequate safeguards, and then be unable to undo what you've released to the world.
Do they? We don't even have single errant actors who go and kill 1000 people. I don't believe human motivations support the idea of killing so many people unrelated to you.
I worked at Anthropic, and I wouldn't attribute much to the structure itself – so I'm wary of using it as a positive example here.
I do attribute a lot to specific people. Concretely, to much of the intitial team, who they recruited on the research/infra side, and some very close personal relationships within research/infra. That dynamic, paired with their unwillingness to accede to something against their values, is what I credit for some atypical decisions and outcomes [1].
Things regulary go "corrupt" in parts of the company; it's hard to scale without importing culture from big tech. Sometimes, the defense was ICs escalating issues, Dario talking to ICs, and then shaking things up.
But this process takes time, and it doesn't lead to a full reversal; a bad/misaligned hire has reverberating impacts. Many folks are still driven by values (even if their values are not your values!), but scaling dynamics seem to be evolving like any other org – just at a higher employee count and revenue numbers.
I do place trust in specific people who work at Anthropic, but I wouldn't place trust in Anthropic the organization. It's an organization that's wont to change, regardless of its structure.
Totally agree about the people. I've seen a bad hire blow up a 20 person startup. I've seen 5 person company excel since they worked more like 5x5 persons than 5 individuals.
The policy decision to silently nerf AI/ML code produced by Fable surely wasn't just something "accidentally imported via a bad hire"? It seems to me like Anthropic wants to control who can develop frontier AI models. Maybe from inside Anthropic that seems like a noble mission, but from the outside it seems like downright shady anti-competitive behavior.
I saw in latest news the decision has been partially reversed -- because of external pressure...
My point was that Anthropic has tended to make atypical decisions vs. its peers, not that they're always the right decisions. The direction of those decisions has tended towards assuming exponential growth of AI will continue and a certain flavor of AI safety.
This decision does seem in line with what I would expect from Anthropic, so I don't see it as a sign of changing values – even if I personally disagree.
Having values doesn't mean they're "the right" values nor the same as your values.
Regardless, it's still atypical in the context of an American company, and it can help explain the differences between Anthropic and its peers. That doesn't mean I agree with their decisions or that they're "the right" decisions, but I think it's a helpful framing in which to understand them.
I think the difference is the ability to be persuaded by a strong argument that you've critically evaluated.
Some people are unjustly called stubborn when they don't change their position based on a weak argument from an authority figure. And others claim values, but they're just stubbornly adhering to something that feels good to believe.
Your comment is very astute. A structure is like a shell. It can only protect what is within. It does not cause what's within to be vital, healthy, or unhealthy. But if you think that the courage that Dario has regularly shown would be possible with a conventional "best practices" structure, I think you're kidding yourself.
> But if you think that the courage that Dario has regularly shown would be possible with a conventional "best practices" structure, I think you're kidding yourself.
With respect to OP (who has a unique vantage from inside), I do agree with this on principle. When there are uncommon outcomes, there must be uncommon structure imho. A "good structure" is like oxygen, water, or peace: When it's well-maintained and well-distributed, one might not even notice it's there, nor spend much time being grateful for it. It's banal, but "what do you mean? isn't this just how things would always have been?" is both beautiful and tragic.
Imho if we could figure out how to have a "loud peace" (in all the ways that this might mean), we'd have figured out an important way of sustaining the world and ourselves.
The structure requires maintenance and that is done by an individual or individuals. The real reasons a good company stays good is because the leadership stays good. When the leadership begins to disengage or leaves or changes in some way then the structure will begin to break down. You can't fix it with a "better" structure. It will decay over time unless someone is actively maintaining it.
What you say is true, but there is more to it. Decay is not the only thing that can happen to a structure. It also can be actively destroyed from the outside. Rather than ask whether a structure is right or wrong, good or bad, we instead need to learn to ask whether it is strong or weak.
I get the sense you were feeling at odds with my framing? I wonder if it's that you're picking up that I believe "structure" is above any one person or set of people. In my conception, leadership is just part of structure, a key maintainer. Leadership are pieces of the structure, but subordinate in scale. They sometimes seek outside help in shaping structure (e.g., ppl like eries), and the structure becomes like another passive actor, not simply "leadership's doing". Leadership are key players taking care of the structure, but they are just one set of players, and in some structures, non-leadership employees play an outsized role (often because leadership knew enough to step back). Sometimes the role of leadership if "fucking right off" in certain domains. Regardless, the structure then guides behaviour of all within it, and hopefully the structure also maintains us, at least as much as we maintain it.
I'm stating the above as if it's universally true, but it's just my take. I'd be curious to know if any parts give you strong YES or NO feelings, if you are open to share your gut reaction. Blunt responses welcome
In all seriousness, yes, individual leadership at the top has to be willing to steelman controversial issues and potential changes of direction, as well engage in unapologetic gatekeeping. At this point we've seen this over and over in tech when observing corporate successes and failures.
> If you think that the courage that Dario has regularly shown would be possible with a conventional "best practices" structure, I think you're kidding yourself.
Is there something that happened which you don't think would have come to pass with a standard PBC/C-Corp (without the LTBT)? I'm trying to think of one, but nothing is coming to mind.
I think the structure attracted many people to Anthropic (e.g. an RSP that could only be overridden by the LTBT), but I'm not sure it has demonstrated a practical impact.
As an aside, I think a lot about this problem too! But the answers that don't reduce to something like "the people, and the people to whom they give power" seem to break down when I look closely.
I was at Google when it pulled out of China. GP's post reminds me a lot of early Google - it wasn't evil because there were people in high places, who were critical to its operations, who cared deeply about doing the right thing, and as a result other people who cared about doing the right thing felt like they had cover, and people who were willing to do the wrong thing to hit a short-term number found that they were marginalized. It changed slowly, one departure at a time, as the wrong people got into positions of power and started providing cover to people willing to do the wrong thing. A lot of it also had to do with declining market power: when Google was universally on top, they felt like they could do the right thing without serious negative consequences, but when they were fighting for control of a market, they felt they had to make compromises lest some other firm (being honest: Facebook) would end up in power and do the wrong thing anyway.
Unfortunately there doesn't really seem to be a cure for institutional decay. Once unethical people get in power, they hire other unethical people, and then you're just stuck in Game of Thrones. You have to go quit and found another company, and single-mindedly keep all those people away, kinda like Anthropic did when they left OpenAI.
> A lot of it also had to do with declining market power: when Google was universally on top, they felt like they could do the right thing without serious negative consequences, but when they were fighting for control of a market, they felt they had to make compromises lest some other firm (being honest: Facebook) would end up in power and do the wrong thing anyway.
I would argue it's not a real value if you are not willing to lose something in order to hold on to it. It is admirable to want to do the right thing when you can get away with doing the wrong thing. It is only a true value if you are willing to do the right thing when you cannot get away with doing the right thing.
> I would argue it's not a real value if you are not willing to lose something in order to hold on to it. It is admirable to want to do the right thing when you can get away with doing the wrong thing. It is only a true value if you are willing to do the right thing when you cannot get away with doing the right thing.
I don't think it's that simple.
For example, let's say your desire is to minimize harm in Area X. While you're on top and in control of Area X, then you can do that easily enough. Suddenly a competitor comes whose values show they're willing to do lots of harm to Area X. And if they beat you in the capitalistic marketplace and gain more control, they'll be able to do lots of harm. In order to beat them, you may have to do a little bit of harm to Area X, which goes against your values. But in doing so, you retain control, and prevent even greater harm to Area X. Is that not a "real" value?
Would it be a "real" value to staunchly refuse to do a little harm to Area X, even if you know that this will result in greater harm in the long run?
This is why I distrust simple ideologies. The world is not simple.
Your logic doesn't hold up well to simple escalation logic.
Company A founds itself on doing 0 harm to Area X. Competitor B shows up and starts finding success doing 10 harm to Area X, so Company A makes a "moral" decision: If we do 9 harm to Area X, we are preventing 1 entire harm. Isn't that real value? then Company C shows up and starts finding success doing 100 harm to Area X, so Company A changes it's moral stance to "unless we do 99 harm to Area X ..."
I know an old lady who swallowed a fly kind of logic going on here.
> then Company C shows up and starts finding success doing 100 harm to Area X, so Company A changes it's moral stance to "unless we do 99 harm to Area X ..."
I mean yes this is technically possible. But I think in many cases, especially "winner-take-all" markets like online search engines, social networks, etc., you don't get this large number of repeated threats. Fending off a competitor or two might be enough. And just as it's possible for there to be some advantage that opens from doing 99 harm to Area X, it's also possible that it never happens.
But also, let's pretend the hypothetical you say _did_ happen?
What should occur? Should the company just NOT do 99 harm to Area X and instead allow 100? If so, why? Unless you break the hypothetical by adding some alternative option C, as much as we don't like the preventative-99 option, it's still better than the allowing-100 option.
I mean, your proposed logic seems to be quite consistent from a basic game theory perspective. Defecting in a prisoners dilemma and races to the bottom are both well observed phenomena.
We have 10,000+ years of human civilization at this point. There must be some other active ethical maxim operating other than "choose the lesser of two evils" to explain why there is so much cooperation amongst humans. Evidence is not on the side of the preeminence of races to the bottom.
You should investigate the repeated prisoners dilemma.
> You should investigate the repeated prisoners dilemma.
Well aware. Obviously, the entirety of human civilization is a bit more complicated than a prisoners dilemma, iterated or not. Yet prisoners dilemma's and races to the bottom still exist, and it makes no sense to argue against them in the abstract.
I think we are very disconnected on the topic of conversation here. Somehow you've confabulated my point with an attack on the prisoners dilemma or races to the bottom?
The person I was responding to made the point that if you want to minimize evil in the world, sometimes you have to add evil to a lesser degree. As in my example, if I do 9 points of evil but prevent 10 points of evil then according to OP I've added value to the world in the form of the 1 point of evil I have reduced.
I responded that this can lead to an escalation trap. This assumes that we would all prefer less evil in the world, right? So how do we get out of the escalation trap? Repeated application of the maxim "always do a bit less evil than the worst possible competitor" will not lead to a minimization of evil overall, only a creeping increase in the total amount of evil in the world.
How are you equating this to me arguing against the existence of races to the bottom?
> It is only a true value if you are willing to do the right thing when you cannot get away with doing the right thing.
In reality, neither corporate nor personal values are binary, all-or-none propositions. They are more like springs that push you in the right direction. But if something pulls hard enough in the wrong direction, a spring can be overpowered.
I don't know, man. There seem to be enough exceptions in the world to make me at least curious about whether this is really true. For what it's worth, the story of Google and "Don't Be Evil" is in the book.
Yeah, I lean towards the structure not being the cause of the outcome here (i.e. if you rotated the governance structure of Anthropic and OpenAI, I think the decisions at each would likely stay the same).
If they made that decision and it destroyed revenue, I could see an alternate timeline where a standard C-Corp + board with non-founder control may have ousted leadership. But that wasn't the situation for OpenAI or Google either, and their leadership still made a different decision.
> scaling dynamics seem to be evolving like any other org – just at a higher employee count and revenue numbers.
I really wonder if it's possible to avoid these dynamics, even if you try really hard.
If not, it seems to me that goal alignment is the main benefit of a hypothetical lean AI company where the middle management is 1% people and 99% tokens. When most of your decision-making is not being siphoned by politics, your output scales far better with respect to input resources.
(This isn't a dig on managers; I've been one. But if a situation doesn't naturally escalate, that usually means a manager in the chain chose not to escalate it, and their reports have to go around them.)
Not sure this holds, sadly. I spent a few months reporting serious security bugs as model capabilities took off earlier this year, and only ~half were fixed. The unfixed bugs were just as critical as the fixed ones; sometimes they were even two similarly critical bugs at the same company, and only one would be fixed!
On your other point, the government still has systemic leverage and can compel access, so this doesn't remove that risk.
That doesn't mean this is the end of the world, and some balance of power is usually good. But I do think it will still increase the capabilties of rogue actors and their net harm.
While this makes it easier for Anthropic to detect misuse, it also means that the US government and other parties have access to every message and response from every user.
This applies even with API usage through third-party inference providers (e.g. AWS' Bedrock and GCP's Vertex) or with a zero-day data retention agreement in place.
I understand the reasoning for doing this, but I don't love the precedent that it sets.
It will also cause a lot of trouble for companies with specific data access policies (probably most large companies). My money is on this new thing getting gutted very quickly as they figure out how much this constraint cuts into their bottom line.
I'm late to this thread, but the post seems to skip the section about risks/mistakes/incidents with restricting Claude's access with containers ("pattern 1"). Doing this properly is still hard!
For example, Anthropic has shipped several bugs that allow any claude.ai/code session – which are isolated in ephemeral containers – to access and exfiltrate all of the user's other sessions, connected repos, and environment variables. The rogue/hijacked Claude could also spawn new Claude sessions with arbitrary instructions and access, regardless of the original session's constraints.
I originally wrote about this (with permission) in February[1], and most of the issues were quickly fixed. But the underlying token scope issues have regressed several times since then – including post-Mythos – so I wouldn't say that Anthropic has solved this yet.
GLM 5.1 is surprisingly capable. Anecdotally, I couldn't notice a difference until ~120K tokens.
Qwen 3.6 35B A3B also exceeded my expectations. It's surprisingly performant, even though the previous generation wasn't even able to use the testing harness.
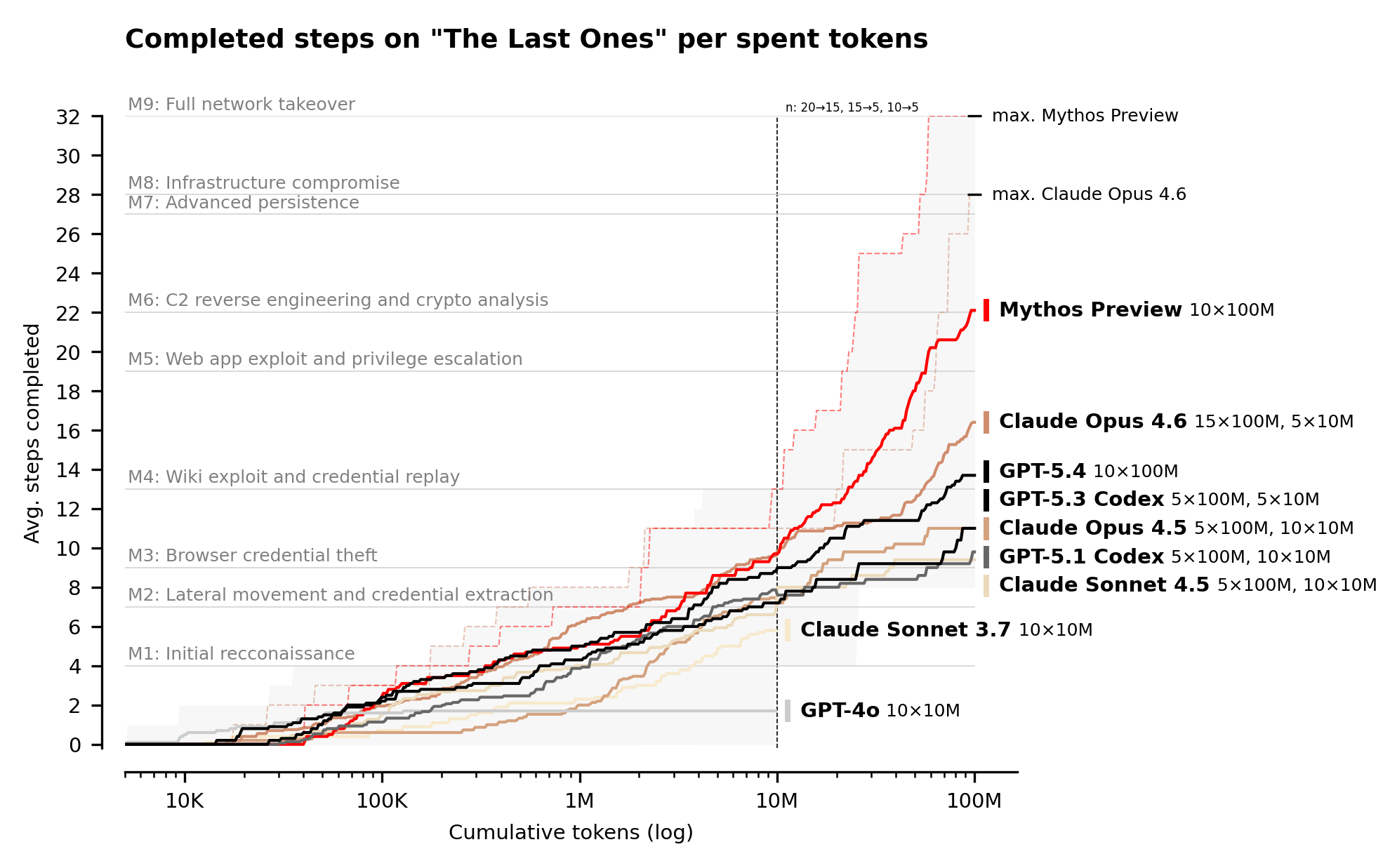
I think the third chart is the most notable; Mythos is the first model which saturated that eval from the UK AISI [1].
Personally, I think we crossed the threshold of meaningfully useful capabilities for autonomous hacking with Opus 4.6 [2], mostly because its behaviors and persistence are useful for finding vulnerabilities out of the box [3]. But it still seems like Mythos is another step up.
A plateau is unlikely, at least for cybersecurity. RL scales well here and is replicable outside of Anthropic (rewards are verifiable, so setting up the training environment doesn't require that much cleverness).
The post also points out that the model wasn't trained specifically on cybersecurity, and that it was just a side-effect – so I think there's still a lot of headroom.
It's scary, but there's also some room for cautious non-pessimism. More people than ever can cause billions of dollars of damage in attacks now [1], but the same tools can be used for defensive use. For that reason, I'm more optimistic about mitigations in security vs. other risk areas like biosecurity.
{kind=link}
So even if GPT 5.5 is just as capable in these scenarios (which, imo, it largely is), it is not known by the government apparatus as having the same capabilities.
Personally, I think we crossed the threshold of capabilities with Opus 4.6 [2], which translated to an even more capable open-weight GLM 5.1 (which it is rumored to have distilled Opus 4.6) [3][4]. But the USG and its partners aren't fully rational actors with perfect data, so it's possible they're only viscerally aware of these capabilities in the context of Mythos.
[1]: https://www.reuters.com/business/us-security-agency-is-using...
[2]: Opus 4.6 was used for https://www.noahlebovic.com/testing-an-autonomous-hacker/
[3]: See GLM 5.1 scoring in https://www.cybergym.io/cybergym/
[4]: https://dualuse.dev/posts/chinese-models-are-sometimes-bette...
reply